Large language models aren't junior developers. They're something fundamentally weirder and more constrained than that.
Understanding these constraints is critical. Without this knowledge, you'll blame the model, the provider, or Claude Code itself when things go wrong. In reality, you're probably working against the model's nature instead of with it.
The constraints of LLMs force you to improve your codebase quality, structure your context carefully, and design feedback loops into your workflow. Get these wrong, and you'll end up with garbage output. Get them right, and Claude Code becomes a genuinely powerful coding partner.
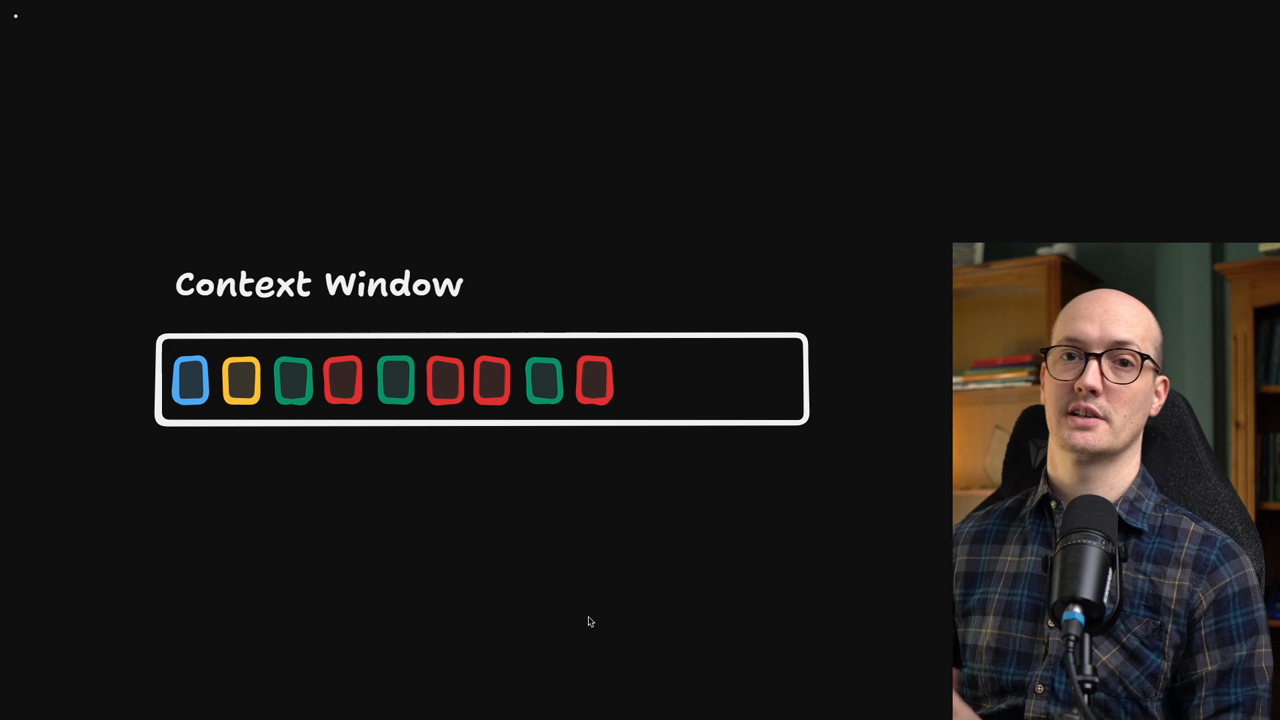
The smart zone is where the model has enough attention budget to work sharply. The dumb zone is where attention relationships become strained and reasoning degrades.
With a 200,000 token limit, the smart zone typically extends to around 80,000 tokens. Beyond 80-90% of your context window, you're in serious trouble.
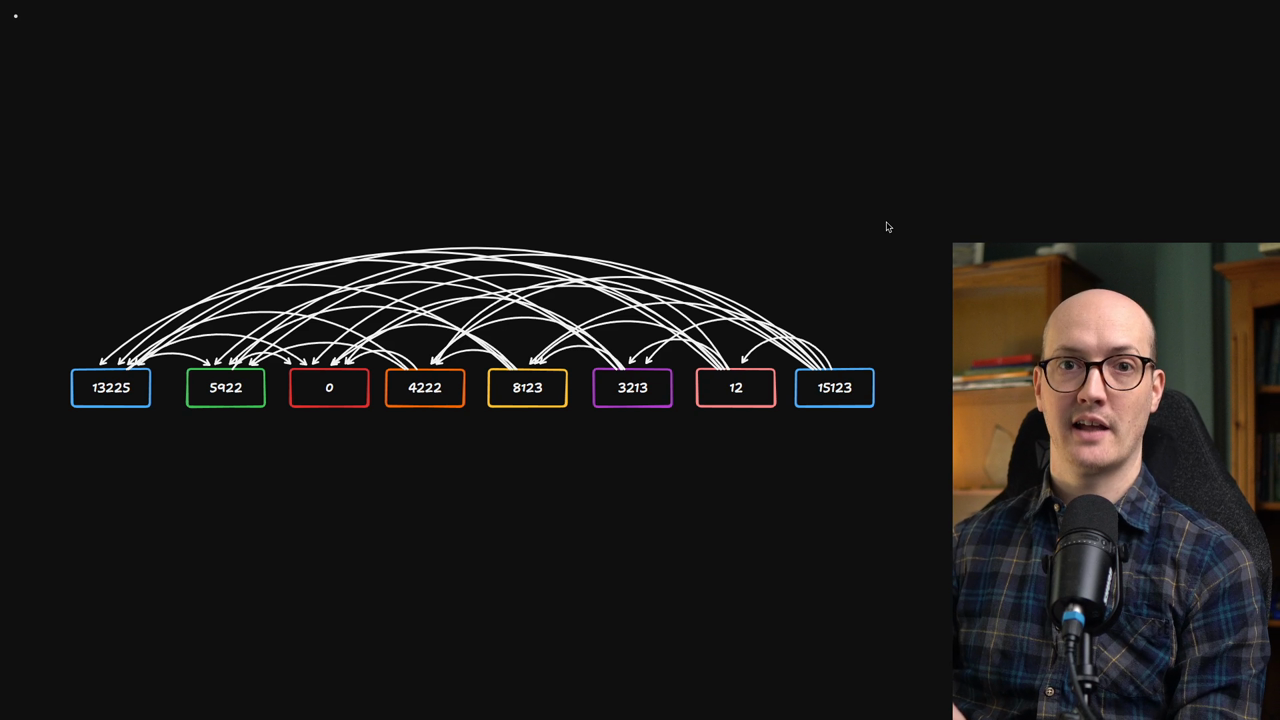
Think of it like a football league where every new team has to play every other team. Adding tokens scales quadratically, not linearly.
Hallucinations aren't bugs. They're what happens when you ask an LLM about information outside its fuzzy, compressed knowledge. The model wants to help so badly that it fills gaps with plausible-sounding nonsense.

Write down three examples of hallucinations you've seen or could imagine seeing in Claude Code (inventing methods, getting API structure wrong, etc.).
LLMs have read all of the internet's public knowledge but compressed it down to a blurry JPEG. They can't reliably recall information from their training data. The only information they see sharply is what's currently in the context window. Write down why this means you need to include documentation and code examples in your prompts instead of relying on the model's memory.
Every new conversation is a blank slate. Claude Code is like a new developer joining your team every 20 minutes with zero institutional knowledge.